Multimodally Grounded Language Technology
Multimodally Grounded Language Technology - MGLT
Background
The basic scientific question of the MGLT project is how to computationally model the interrelated processes of understanding natural language and perceiving and producing movement in multimodal real world contexts.
An important problem in language technology and in computer science in general is that in most cases computer systems processing symbols or language do not have access to the phenomena being referred to. In contrast, human beings can readily associate expressions with their nonlinguistic experiences. As a direct consequence, the computational systems can only reason about the symbols themselves rather than about the meaning or external references of those symbols.
Objectives
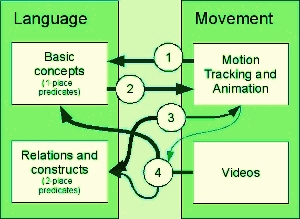
- The main objective of the MGLT project is to develop methods and technologies to automatically associate human movements detected by motion capture and in video sequences with their linguistic descriptions.
- When the association between human movement and their linguistic descriptions has been learned using pattern recognition and statistical machine learning methods, the system can also be used to produce animations based on written instructions and for labeling motion capture and video sequences.
- The link between movement and language is also examined in relation to the context and the quality and nature of the movement.
- The project also plans to create a library of movements with their corresponding labels that can be used for the development and training of the machine learning methods in the project and later distributed to benefit the scientific community.
Team
The project team consists of researchers from the Departments of Information and Computer Science and Media Technology at Aalto University School of Science.